Each organization in the global community of Crossref members (that’s currently over 24k organizations in 166 different countries) plays a key role in building the Research Nexus. Any opportunity we have to meet with our members in person is a highlight and a way for us to learn more from each other. The month of January saw three of us travel to Bangkok to attend the first-ever Charleston Conference organised in Asia and to meet with our growing community in Thailand.
This year, we placed a spotlight on the Latin American community, hosting the second Crossref Metadata Sprint in São Paulo, Brazil from 4 - 6 March 2026. In our first tri-lingual event, we brought together 31 participants from Argentina, Brazil, Colombia, Ecuador, and Mexico. Our goal was to foster community co-creation using the open scholarly metadata. The Sprint was an opportunity to pose questions, share ideas, collaborate on research, and propose innovative solutions that enhance the use of metadata in scholarly communication and beyond.
Read on for more details about the content of the Sprint, and the resulting projects. You can also register to join our Sprint Showcase call on 22nd April to hear directly from the team about their creations.
On 17 March 2026, we experienced an outage that affected DOI resolution for Crossref DOIs and the deposit of metadata records by Crossref members. In this summary, we outline what happened, the impact on our community, and the steps we are taking to strengthen our systems and processes as a result.
We’re excited to announce a new data citation API endpoint and are seeking your feedback. The new service makes existing data citation relationships in our metadata available, thereby surfacing this part of the research nexus. At the same time, we’ve decided that it’s time to move on from Event Data.
To work out which version you’re on, take a look at the website address that you use to access iThenticate. If you go to ithenticate.com then you are using v1. If you use a bespoke URL, https://crossref-[your member ID].turnitin.com/ then you are using iThenticate 2.0.
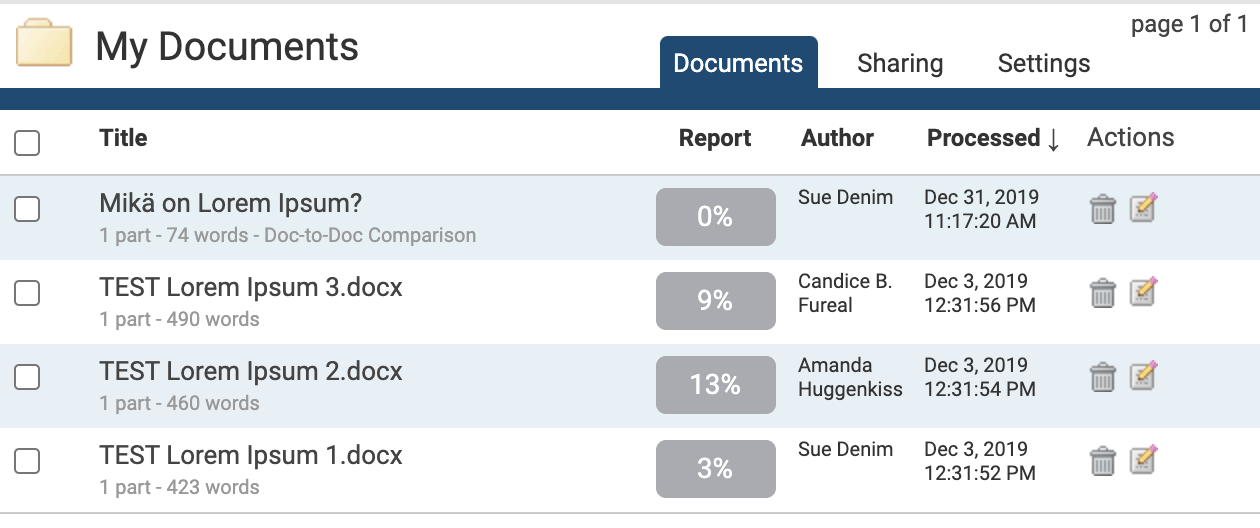
Within a folder, the Documents tab shows all the submitted documents for that folder.
Each document submitted generates a Similarity Report after the document has been through the Similarity Check. If more documents are present than can be displayed at once, the pages feature will appear beneath the documents - click the page number to display, or click Next to move to the next page of documents.
zip file upload - to submit a zip file containing multiple documents, up to a maximum of 100MB or 1,000 files. Larger files may take longer to upload
cut & paste - to submit text directly into the submission box. Use this to copy and paste a submission from a file format that is not supported. This method supports plain text only (no images or non-text information)
iThenticate currently accepts the following file types for document upload:
Microsoft Word® (.doc and .docx)
Word XML
plain text (.txt)
Adobe PostScript®
Portable Document Format (.pdf)
HTML
Corel WordPerfect® (.wpd)
Rich Text Format (.rtf)
Each file may not exceed 400 pages, and each file size may not exceed 100 MB. Reduce the size of larger files by removing non-text content. You can’t upload or submit to iThenticate files that are password-protected, encrypted, hidden, system files, or read-only.
.pdf documents must contain text - if they contain only images of text, they will be rejected during the upload attempt. To check, copy and paste a section of the .pdf into a plain-text editor such as Microsoft Notepad® or Apple TextEdit®. If no text is copied over, the selection does not contain text.
To convert scanned images of a document, or an image saved as a .pdf, use Optical Character Recognition (OCR) software to convert the image to text. The conversion software can introduce errors, so manually check and correct the converted document.
Some document formats can contain multiple data types, such as text, images, embedded information from another file, and formatting. Non-text information that is not saved directly within the document will not be included in a file upload, for example, references to a Microsoft Excel® spreadsheet included within a Microsoft Office Word® document.
Use a word-processing program to save your file as one of the accepted types listed above, such as .rtf or .txt. Neither file type supports images or non-text data within the file. Plain text format does not support any formatting, and rich text format allows only limited formatting.
When converting a file to a new format, save it with a different name from the original, to avoid accidentally overwriting the original file. This is especially important when converting to plain text or rich text formats, to prevent permanent loss of the original formatting or image content of the file.
Page maintainer: Kathleen Luschek Last updated: 2020-May-19