Each organization in the global community of Crossref members (that’s currently over 24k organizations in 166 different countries) plays a key role in building the Research Nexus. Any opportunity we have to meet with our members in person is a highlight and a way for us to learn more from each other. The month of January saw three of us travel to Bangkok to attend the first-ever Charleston Conference organised in Asia and to meet with our growing community in Thailand.
This year, we placed a spotlight on the Latin American community, hosting the second Crossref Metadata Sprint in São Paulo, Brazil from 4 - 6 March 2026. In our first tri-lingual event, we brought together 31 participants from Argentina, Brazil, Colombia, Ecuador, and Mexico. Our goal was to foster community co-creation using the open scholarly metadata. The Sprint was an opportunity to pose questions, share ideas, collaborate on research, and propose innovative solutions that enhance the use of metadata in scholarly communication and beyond.
Read on for more details about the content of the Sprint, and the resulting projects. You can also register to join our Sprint Showcase call on 22nd April to hear directly from the team about their creations.
On 17 March 2026, we experienced an outage that affected DOI resolution for Crossref DOIs and the deposit of metadata records by Crossref members. In this summary, we outline what happened, the impact on our community, and the steps we are taking to strengthen our systems and processes as a result.
We’re excited to announce a new data citation API endpoint and are seeking your feedback. The new service makes existing data citation relationships in our metadata available, thereby surfacing this part of the research nexus. At the same time, we’ve decided that it’s time to move on from Event Data.
Continuing our blog series highlighting the uses of Crossref metadata, we talked to David Sommer, co-founder and Product Director at the research dissemination management service, Kudos. David tells us how Kudos is collaborating with Crossref, and how they use the REST API as part of our Metadata Plus service.
Introducing Kudos
At Kudos we know that effective dissemination is the starting point for impact. Kudos is a platform that allows researchers and research groups to plan, manage, measure, and report on dissemination activities to help maximize the visibility and impact of their work.
We launched the service in 2015 and now work with almost 100 publishers and institutions around the world, and have nearly 250,000 researchers using the platform.
We provide guidance to researchers on writing a plain language summary about their work so it can be found and understood by a broad range of audiences, and then we support researchers in disseminating across multiple channels and measuring which dissemination activities are most effective for them.
As part of this, we developed the Sharable-PDF to allow researchers to legitimately share publication profiles across a range of sites and networks, and track the impact of their work centrally. This also allows publishers to prevent copyright infringement, and reclaim lost usage from sharing of research articles on scholarly collaboration networks.
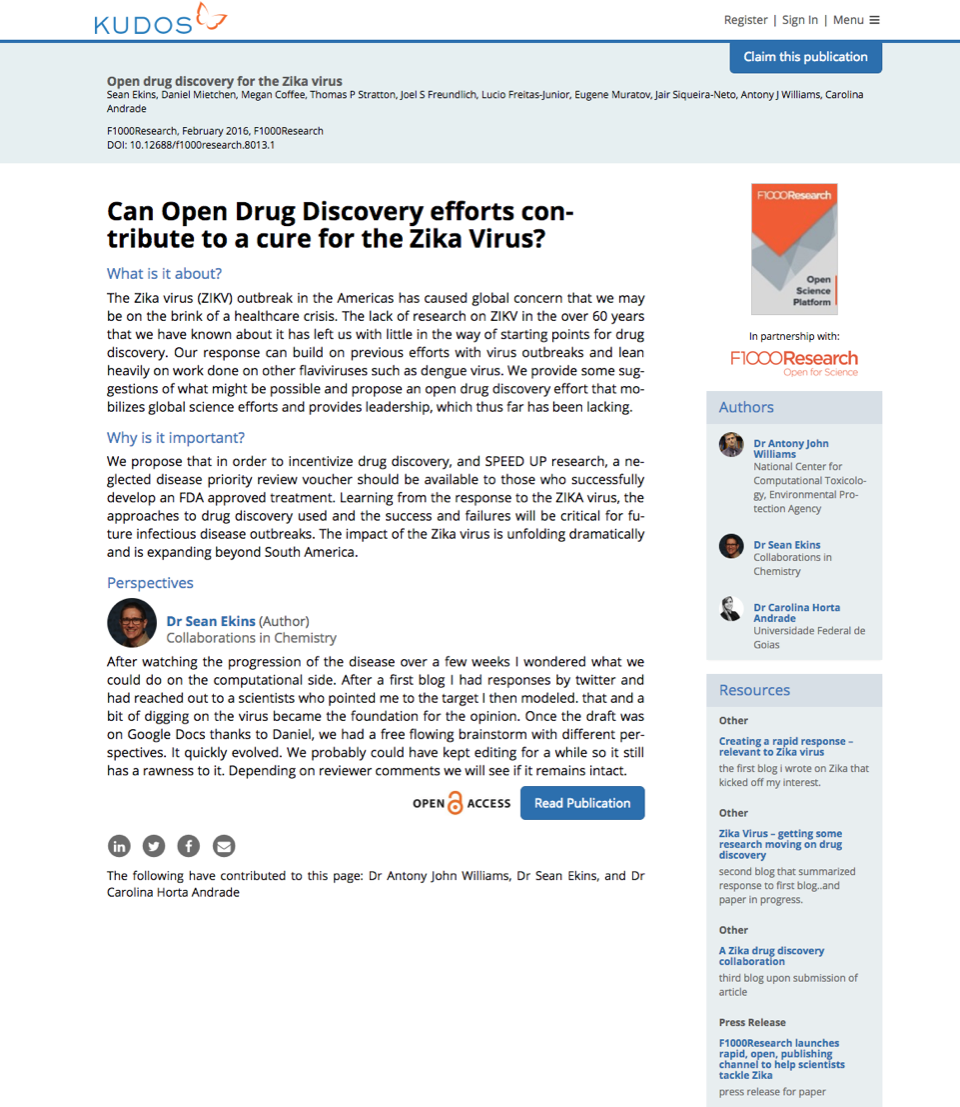
An example of a Kudos publication page showing the plain language summary
How is Crossref metadata used in Kudos?
Since our launch, Crossref has been our metadata foundation. When we receive notification from our publishing partners that an article, book or book chapter has been published, we query using the Crossref REST API to retrieve the metadata for that publication. That data allows us to populate the Kudos publication page.
We also integrate earlier in the researcher workflow, interfacing with all of the major Manuscript Submission Systems to support authors who want to build impact from the point of submission.
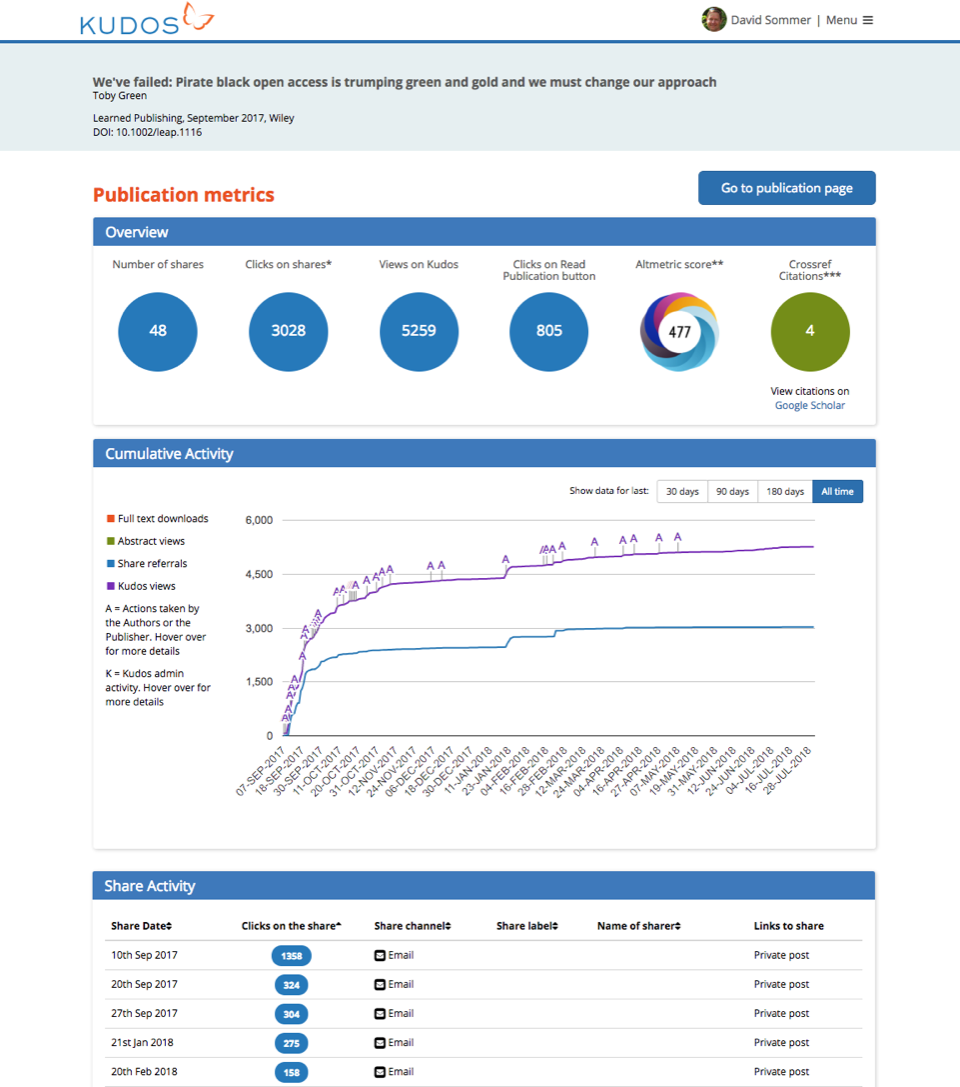
More recently, we started using the Crossref REST API to retrieve citation counts for a DOI. This enables us to include the number of times content is cited as part of the ‘basket of metrics’ we provide to our researchers. They can then understand the performance of their publications in context, and see the correlation between actions and results.
A Kudos metrics page, showing the basket of metrics and the correlation between actions and results
What are the future plans for Kudos?
We have exciting plans for the future! We are developing Kudos for Research Groups to support the planning, managing, measuring and reporting of dissemination activities for research groups, labs and departments. We are adding a range of new features and dissemination channels to support this, and to help researchers to better understand how their research is being used, and by whom.
What else would Kudos like to see in Crossref metadata?
We have always found Crossref to be very responsive and open to new ideas, so we look forward to continuing to work together. We are keen to see an industry standard article-level subject classification system developed, and it would seem that Crossref is the natural home for this.
We are also continuing to monitor Crossref Event Data which has the potential to provide a rich source of events that could be used to help demonstrate dissemination and impact.
Finally, we are pleased to see the work Crossref are doing to help improve the quality of the metadata and supporting publishers in auditing their data. If we could have anything we wanted, our dream would be to prevent “funny characters” in DOIs that cause us all kinds of escape character headaches!
Thank you David. If you would like to contribute a case study on the uses of Crossref Metadata APIs please contact the Community team.