We’re excited to announce a new data citation API endpoint and are seeking your feedback. The new service makes existing data citation relationships in our metadata available, thereby surfacing this part of the research nexus. At the same time, we’ve decided that it’s time to move on from Event Data.
Metadata is communication; it can tell a story about research and paint a picture for others to respond to and learn from, across the world and throughout the forthcoming generations. Metadata can feel technical with words like ‘infrastructure’ and ‘schema’, and sometimes, like tech in general, it comes with hyperbole. But metadata really is part art (storytelling and pictures) and part science (structured models and standards) with both aspects being equally important, and requiring people as well as systems. That necessary combination of human and machine involvement also makes metadata challenging.
Once a year we release all metadata records for content registered with Crossref in a public data file. This year’s version, containing nearly 180 million records, is now available. It includes metadata associated with all Crossref-registered DOIs in JSON-lines format.
Crossref Ambassadors act as local points of contact, meeting editors, librarians, researchers, and institutions to help them navigate Crossref services and understand how strong metadata supports visibility, integrity, and trust in research. They explain how to participate in our rich network of connections between works, people, and institutions, in ways that make sense in their own contexts. And last year, being our 25th anniversary, Ambassadors also massively contributed to our celebrations!
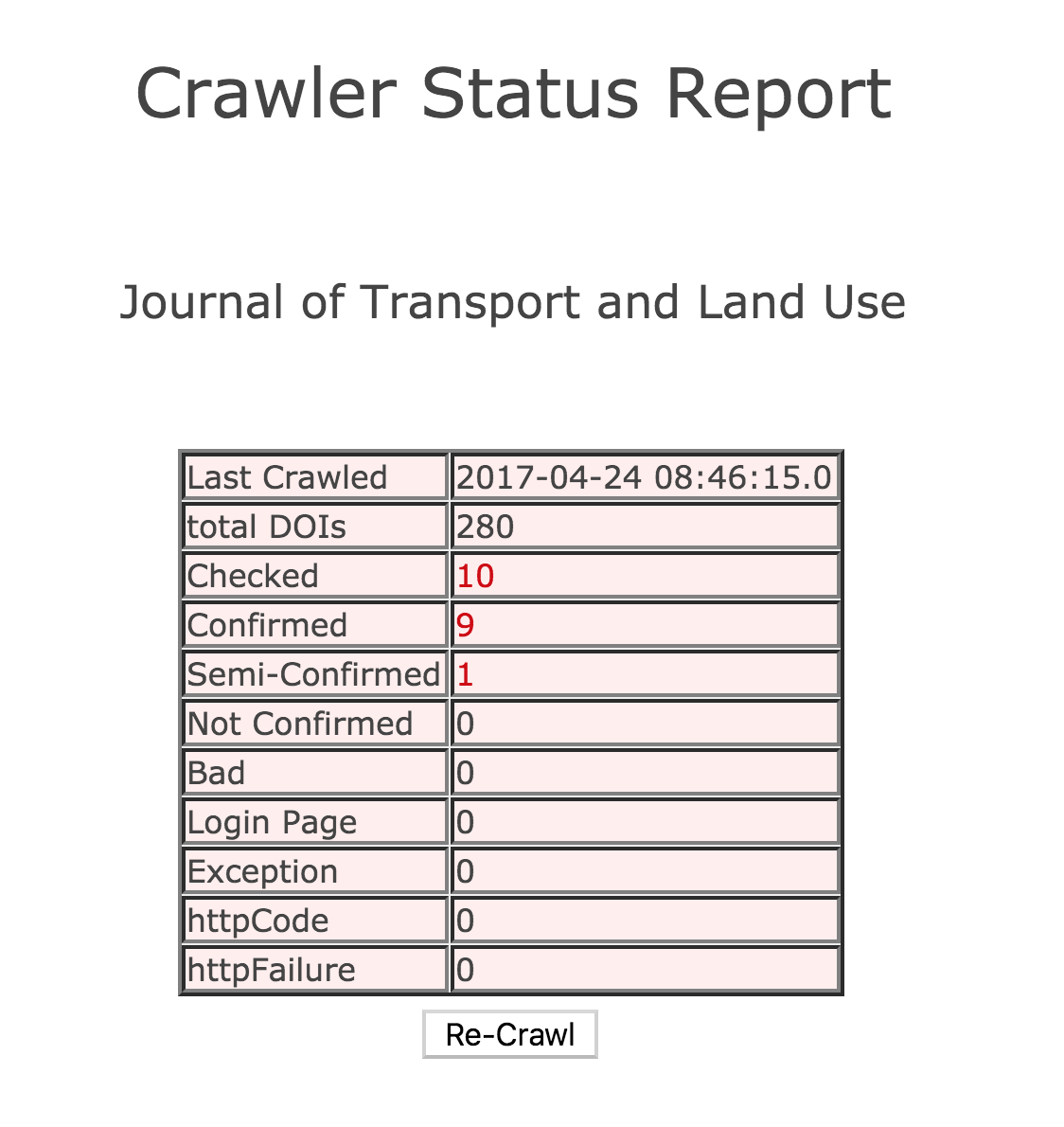
We test a broad sample of DOIs to ensure resolution. For each journal crawled, a sample of DOIs that equals 5% of the total DOIs for the journal up to a maximum of 50 DOIs is selected. The selected DOIs span prefixes and issues.
The results are recorded in crawler reports, which you can access from the depositor report expanded view (access the depositor reports by type at the links below).