PID strategies are being written around the world right now, and the decisions being made will shape the scholarly record for decades. After 25 years running open scholarly infrastructure—now on behalf of 25,000 members in 167 countries—Crossref has an informed perspective on what those decisions should ideally rest on. Today we’re setting it out in our’s first position paper: Persistent identifiers in research infrastructure policy: the need for a holistic approach. You can read it online or download the PDF; it’s a 16-minute read.
Research is rarely limited to a single contributor performing a single role. Behind every research output are people contributing in various ways: software development, data analyses, methodology design, and much more. Often, the same person contributes in several of these ways. Until now, Crossref metadata could only capture part of that picture, but this is changing with Schema 5.5.
Through user experience research (UXR) initiatives that take into account our diverse membership and community, we can have a continuous, deeper understanding of the role of metadata in our members’ workflows, and ensure that our work continues to meet our community’s needs. Your support is the key to this process, and will positively impact the wider community - and if you’d like to start today, you can take part in our latest initiative: help us improve our Events page by sharing your thoughts on the page’s feedback form.
Our 2026 Community Update took place on 13 May. Two calls, one for the eastern and one for the western time zone, highlighted how our global community is growing, how we’re refining the metadata that supports trust in the scholarly record, and connecting records more effectively through our latest tools.
In April 2025, we launched the metadata matching project, in order to add missing relationships to the scholarly metadata. We will do this by consolidating all existing and planned matching workflows, which enrich member-deposited metadata in Crossref. This unified service will result in a more complete research nexus. In this blog post, we share our latest milestone: developing and evaluating a strategy for matching funder metadata to Research Organization Registry (ROR) identifiers.
Key takeaways
Funder matching links funding organisation names to persistent identifiers, helping us understand how research outputs are funded and supported.
We built a new strategy to automatically match funder names in Crossref metadata to ROR identifiers.
This is the first production deployment of Crossref’s new metadata matching framework, paving the way for future matching tasks across affiliations, references, grants, and more.
We did a brief demonstration of the funder matching process at our Community Update Call on 13th May 2026. You can watch a recording thereof on Youtube.
Introduction
In our recent blog post on metadata enrichment, we described the different ways that Crossref metadata can be enriched after its initial deposit, leading to a more complete research nexus. In this model, we can think of the metadata records served through the Crossref API as a result of several layers of enrichment applied on top of the initial deposit from a Crossref member. These layers may include member updates, community feedback, automated matching, and third-party datasets.
Metadata matching (layer 3) is when we use automated strategies to find missing relationships between entities within the scholarly record, such as relationships between research outputs, funding organisations, and grants, based on the unstructured information already present in the metadata. Our matching project aims to create a dedicated, consolidated metadata matching workflow that will eventually replace all existing production matching processes, with results made available through the REST API. We have identified the first six matching tasks that we’d like to tackle: funder name matching, bibliographic reference matching, preprint matching, affiliation matching, grant matching, and title matching.
Funder matching is a task of automatically finding an identifier of a funding organisation based on its name. Funder matching, when done well, improves the coverage and reliability of funding metadata, and the relationships between funding organisations and research outputs in particular. These relationships are critical for understanding how research is supported, tracking compliance with funder mandates, and enabling analyses of research investment.
Funder matching, as any type of matching, is not trivial because data can be noisy: the same organisation may appear under many variants, abbreviations, or translations, and some names are genuinely ambiguous. Our goal was to develop a matching strategy that results in a lot of additional identifiers while maintaining high quality of the results.
As part of this project, we will be switching the target identifier set for funder matching from the Funder Registry to the ROR registry, in line with our long-term plan to replace the Funder Registry with ROR. ROR provides an open, community-governed identifier system that is already used for affiliations and research institutions. It has become a well curated and widely-trusted catalog of organisations around the world involved in research, and it is very well suited to be the primary identifier for funders in Crossref. We are taking this opportunity to make a major move toward using ROR IDs.
This blog post describes the funder matching strategy we’ve developed and presents an evaluation of its performance, along with a new evaluation data set.
Overview of the funder matching strategy
At a high level, the funder matching strategy takes a funder name string from Crossref metadata as input and returns zero or one ROR IDs. While funder strings can occasionally map to more than one ROR ID, this strategy can only return at most one match per input string. Future versions of the strategy will allow for multiple matches.
The new matching strategy is based on the “single search” strategy previously developed at Crossref to match affiliation strings to ROR IDs, which is currently implemented in ROR’s API and which we plan to use to enrich affiliation metadata for works in Crossref. Funder matching and affiliation matching are similar tasks—they share the same target identifier set (ROR IDs), and they both use free-form text strings as their primary inputs. Most of these text strings are in English, so the strategy is optimized for English text; but the matching still works well on text in other languages, thanks in large part to ROR’s comprehensive catalog of multilingual alternate names.
However, there are also some differences in the way that these input strings tend to look across the two different tasks, so the strategy was adapted and refined specifically for funder matching. For example, affiliation strings are often much longer and contain information such as academic department and city/country in addition to the name of the institution; funder strings are usually more concise, which can often make it easy to identify an exact match in ROR, but requires more extensive exclusion criteria to prevent incorrect matches for generic names.
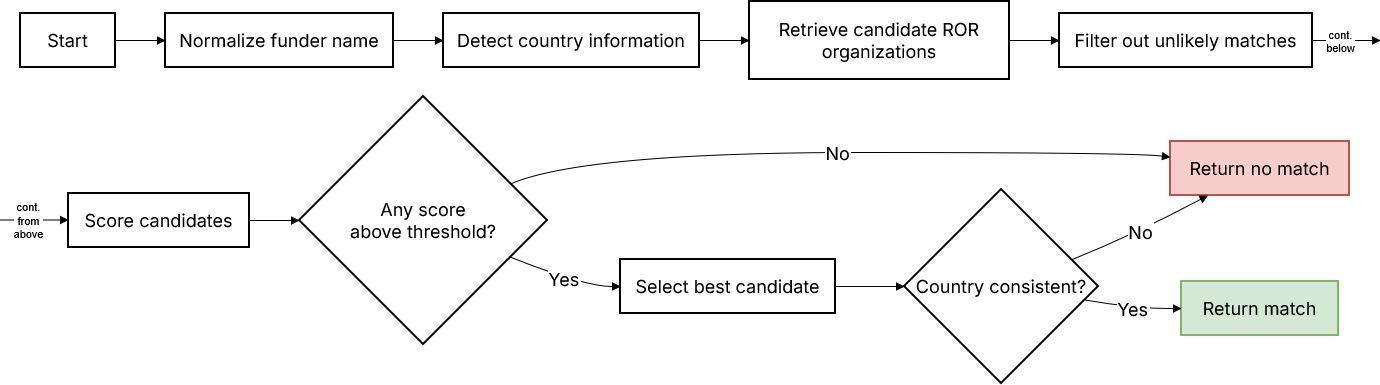
The flow chart diagram shows the basic steps that each funder name goes through when a match is attempted:
Flow chart diagram of the matching strategy’s steps to evaluate a funder name against potential ROR matches
After normalization, the name is compared to a list of country names and identifiers to identify if there is any country information. The name is then passed to a search engine—an indexed text-based search system such as Elasticsearch or OpenSearch—to retrieve a set of 15-20 possible candidates of ROR organisations with similar names. At this point, we use a set of filters to discard any name matches that are unlikely to be correct (i.e., they tend to produce false positives). Some examples include matches for very short names, or names that are very generic (think “Department of Education,” without any other indication of which larger entity it may be a department of).
At this point, we have a set of candidate ROR IDs, with a corresponding set of organization names that may match our funder name. We score these names by their similarity to the input name (using a fuzzy matching algorithm), then select the best candidate based on this score and a few other heuristic measures. As a final step, we ensure that, if we identified any country information in the early stages of the matching, the ROR ID that we matched is consistent—while developing the strategy, we learned that failure to do this would be a significant source of false positives.
A core principle of the matching strategy is that it is relatively conservative: at several points in the pipeline, the strategy can explicitly abstain and return no match. This prioritizes precision over recall; we consider incorrect matches to be more harmful than missing ones. Nevertheless, this strategy will be able to fill in large gaps in the funder data, and we can be confident that we will not be making widespread mistakes. To verify this, we use an evaluation dataset, which is described in the next section.
Evaluation dataset for funder matching
To evaluate the funder matching strategy, we manually labeled an evaluation dataset that maps funder name strings from Crossref metadata to zero, one, or multiple ROR IDs. The funder names were extracted from a July 2025 snapshot of Crossref works metadata, which contains 25.7 million funder entries across 12.4 million works, representing just over 3 million unique funder name strings.
The distribution of funder names is highly skewed: a small number of names appear very frequently, while most appear only a handful of times. Because correct handling of common funders has a disproportionate impact on overall metadata quality, the evaluation dataset is a weighted sample, where each name is weighted by how often it appears without an asserted funder ID.
The final evaluation dataset contains 3,505 funder names, with a total weight of just over 2.1 million funder entries. Each name was manually labeled against the ROR registry, resulting in at least one ROR match for 1,895 names. In addition, for some cases, alternate matches were recorded to support “relaxed” evaluation in ambiguous scenarios.
Evaluation methodology
Evaluation is done by running the matching strategy on all names in the dataset and comparing the results to the manual annotations. The primary metrics are precision, recall, and the F0.5 score, which combines precision and recall while weighting precision more heavily. This reflects the project’s preference to avoid incorrect metadata assertions, even at the cost of lower recall.
In addition to standard (strict) evaluation, the framework supports relaxed evaluation using alternate matches. This is meant to address cases where funder strings might be ambiguous even for a human evaluator, or a matching strategy might identify a parent organisation of a target, which is not an entirely incorrect match.
Evaluation is performed along two independent dimensions. First, results can be calculated in an unweighted mode, where each funder name is treated as equally important, or in a weighted mode, where names are weighted by how frequently they appear without an asserted identifier in Crossref metadata. Second, evaluation can be strict or relaxed, depending on whether only the primary annotated ROR ID is considered correct or whether alternate, manually annotated matches are also accepted. Together, these dimensions produce four possible evaluation modes.
Results
Under relaxed, weighted evaluation, the funder matching strategy achieves a precision of 0.99, recall of 0.81, and an F0.5 score of 0.95.
The table below compares the performance of the matching strategy across four evaluation modes. The Relaxed Weighted mode represents the headline performance (Precision: 0.9897) as it accounts for both the frequency of names in the metadata (weighting) and valid metadata ambiguity (alternates). In practical terms, the results mean that when the strategy produces a match, it is correct (or acceptably close, in cases of genuine ambiguity) roughly 99% of the time.
Evaluation Mode
Precision
Recall
F0.5 Score
False Positives
False Negatives
Unweighted
0.9365
0.6024
0.8430
81
788
Weighted
0.9776
0.7948
0.9346
81
788
Relaxed Unweighted
0.9707
0.6445
0.8815
37
675
Relaxed Weighted
0.9897
0.8094
0.9475
37
675
While precision and recall are essential for understanding matching performance, there are other important considerations that also matter in practice. This strategy also scores high marks in some of these other criteria that we’ve identified:
Openness — The strategy is open source—source code here—and built on open source methods, in accordance with our commitment to POSI.
Explainability/Flexibility — This is not a black box machine-learning model; the steps, detailed in the overview I’ve given earlier, are fairly easy to understand, update, and apply to new data.
Resources/Speed — The strategy is very quick (averaging a matter of milliseconds per match), and does not require large amounts of intense computation or data storage.
From evaluation to production
This work represents more than an isolated matching experiment: it is intended to be the first production deployment of the new metadata matching framework. Bringing funder matching into production will involve not only implementing the strategy described here, but also standing up shared infrastructure for monitoring, iteration, and reuse across future matching tasks. Applying this new matching system across all of Crossref’s current and future funder data will be our next milestone in the project. Beyond that, we will move on to grants, affiliations, references, and more. The work we’re doing now of setting up infrastructure, refining evaluation methods, and working out any kinks as they arise, will all contribute to the momentum of the project. We’re very excited about all the enrichment of the research nexus that lies ahead!