With key milestones achieved in 2025, including the appointment of new Directors of Technology and Programs, a move to the cloud, and some key schema updates, we now have a firm foundation for our next challenge: a redesign of our core technical systems to make them more modern, robust, and easier to maintain and scale.
In an ongoing effort to make more of our operations transparent, we have decided to start sharing summaries of our board meetings on the blog. We already post our board resolutions, but the summaries will give a bit more information on what the board discusses that may or may not show up on the list of resolutions.
A couple of months ago, Ludo Waltman and André Brasil raised some questions about good practices for Crossref DOI registration, asking for input from the scholarly communication community. In this post, Ludo and André reflect on the input received and discuss the approach to DOI registration that the MetaROR publish-review-curate platform is going to take.
As Crossref celebrated its 25th anniversary last year, we are highlighting some of the most active and engaged regions in our global community.
Over the past 25 years, the makeup of Crossref membership has evolved significantly; founded by a handful of large publishers, we now have more than 24,000 members representing 165 countries. Nearly two-thirds of them self-identify as universities, libraries, government agencies, foundations, scholar publishers, and research institutions.
With key milestones achieved in 2025, including the appointment of new Directors of Technology and Programs, a move to the cloud, and some key schema updates, we now have a firm foundation for our next challenge: a redesign of our core technical systems to make them more modern, robust, and easier to maintain and scale.
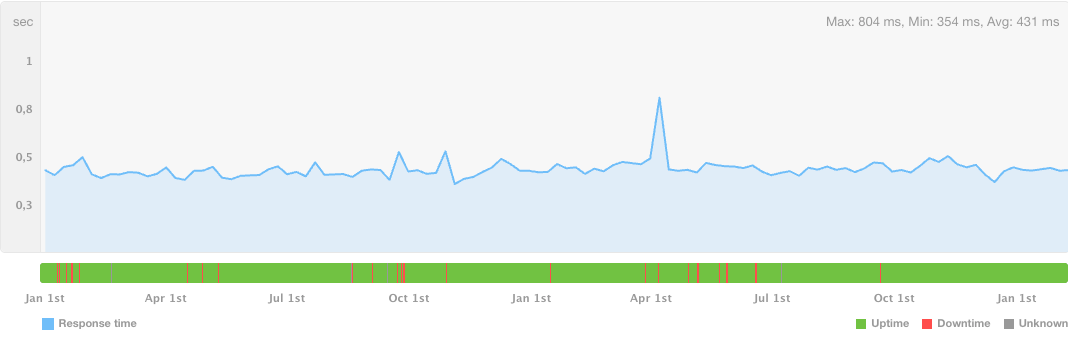
At a high level, our systems serve our community well. The deposit system handles over 107,000 DOI deposits and updates per day, and the REST API responds to 2 billion requests per month, serving up nearly 180 million open metadata records. These systems are reliable: since December 2025, the REST API pools exceeded 99.94% uptime, and the submission queue, since January 2024, has had an uptime of 99.90%.
Uptime for REST API pools and the submission queue, with minimal service interruption since January 2024.
It’s this reliability, we think, that has kept us from tackling this redesign earlier. But the reality is that when these systems were first built, some as long ago as 2005, Crossref and our community looked very different. In 2005, we had 318 members, and were creating DOIs and depositing metadata exclusively for journal articles, all supported by 5 Crossref staff. Today, we have 24,000+ members, representing publishers, societies, funders, universities, service providers, sponsors, and sponsored members; and we are assigning DOIs to >17 content types, from journal articles to book chapters, grants, conference proceedings, dissertations, and more. All supported by 50+ Crossref staff.
Like a stone monolith, a tightly coupled system can be solid, but hard to adapt.
Over the years, we’ve accumulated quite a bit of technical debt building support for new features and functions into one monolithic codebase.
We haven’t always been great at paying down that technical debt (because, as some say, if it ain’t broke don’t fix it), but we have made big strides in the last 18 months. Our main database moved to Postgres from Oracle and we migrated from a physical data centre to the cloud.
But still, the codebase has become hard to maintain; it’s not always clear that fixing something in one place won’t break something else.
A more modern approach, breaking apart the monolith into separate, smaller services, will enable us to seamlessly maintain services, identify and debug issues efficiently, and build new features to support the ever-changing needs of our growing community.
Paul has recently started a new role at Crossref as the Product Manager for the Open and Sustainable Operations Program and will play a big role in this cross-functional effort. Having moved over from the technical support team, he brings a wealth of experience with all of our systems, how they work in detail, and where the pain points exist for internal users as well as members. We will rely on this experience to bring a better suited system to our members and colleagues.
Oh, the things he’s seen (and heard!). Here’s what rises to the top of his pain points list:
Our authentication service is difficult to administer with manual processes still in place for change requests
Title management causes headaches for our members and staff: members can’t modify or transfer titles between each other in our system themselves and rely on manual intervention from the Support team.
Members don’t have access to all of the details about their own records that we have in our system. This creates unnecessary barriers to stewarding their metadata.
Members can’t currently programmatically check the status of their submission in the system to learn in real-time whether it has been deposited or remains in the queue, which would be really useful.
How are we going to do this?
This won’t be one big bang – the scale is way too big, and it’s far too risky. We will instead break the work into a series of (many!) smaller projects, chipping away at the large monolith of Crossref code and building smaller, free-standing components which will be easier to maintain. We also don’t see this work as a separate project with a cleanly defined beginning and end - rather, gradually replacing parts of the system with more modern, better-designed components is simply part of ongoing maintenance.
We’ve already taken a hard look at what our system does (and it’s a lot!) and developed a list of ~14 core “functions” it serves, things like authentication and authorization, metadata deposit and validation, metadata distribution, and so on. We’ll work on replacing those functions with free-standing services, then pull out the (then-unnecessary!) code from the codebase. At each step, the monolith gets smaller and less complex.
We’ve already started doing this, and it feels great! Most recently, we rebuilt a component we lovingly call the ‘Pusher.’ Its function is to push the XML our members deposit to the REST API, where it can be distributed to users, and to keep citation counts updated. We deployed the new Pusher in two phases, in October 2025 and February 2026. It uses modern code libraries, is open source, and runs independently rather than being tangled up with the rest of the core system.
Another project that is currently underway is rebuilding of our metadata matching workflows using modern software development and data science practices. The goal is to create a dedicated, consolidated matching service that will eventually replace all existing matching processes, with results made available through the REST API. This project will start with matching funder names to ROR IDs, and eventually cover also bibliographic reference matching, preprint matching, affiliation matching, grant matching, and title matching.
We have yet to decide on the exact order of things, but that will likely be determined by the complex dependencies we touched on earlier. We’ll also consider urgency and risk - is something falling over too often and causing too much work to maintain it and keep it stable? That’s the reason we bumped up the priority on the Pusher work and rewrote it when we did. We’ll also consider benefits: quicker upgrades which will help both ourselves and our members will naturally have a higher priority than less impactful projects.
We do know that the top priority is the authentication service. The current one was not meant to be permanent, but rather a bridge until we build a permanent solution. It’s now beyond its useful life: it’s quite confusing, it doesn’t scale (and we are scaling), and it’s painful for sponsors, members, and Crossref staff. Tackling this piece of work first unblocks a lot of other important things we want to get done. It’s a big undertaking that we are excited to get started on to improve the user experience for everyone. Importantly, we will be consulting with the community along the way so that we get this right.
Dominika Tkaczyk, Crossref Director of Technology, emphasized the importance of maintaining open scholarly infrastructure at the Crossref annual meeting in October 2025. She said that, just as we maintain roads and bridges to make sure they’re safe, we must maintain scholarly infrastructure so it continues to serve the community far into the future.
This is a long road, but it’s one we’re excited to be on. We’ll have periodic updates on our progress as this work goes forward: what we’re getting done, where we need input, and what we’re tackling next. We’ll need a lot of feedback from you, our community, about what’s working well and where we might make improvements.