13 minute read.Aligning OpenSearch and SRU
[Update - 2009.06.07: As pointed out by Todd Carpenter of NISO (see comments below) the phrase “SRU by contrast is an initiative to update Z39.50 for the Web” is inaccurate. I should have said “By contrast SRU is an initiative recognized by ZING (Z39.50 International Next Generation) to bring Z39.50 functionality into the mainstream Web“.]
[Update - 2009.06.08: Bizarrely I find in mentioning query languages below that I omitted to mention SQL. I don’t know what that means. Probably just that there’s no Web-based API. And that again it’s tied to a particular technology - RDBMS.]
(Click image to enlarge.)
There are two well-known public search APIs for generic Web-based search: OpenSearch and SRU. (Note that the key term here is “generic”, so neither Solr/Lucene nor XQuery really qualify for that slot. Also, I am concentrating here on “classic” query languages rather than on semantic query languages such as SPARQL.)
OpenSearch was created by Amazon’s A9.com and is a cheap and cheerful means to interface to a search service by declaring a template URL and returning a structured XML format. It therefore allows for structured result sets while placing no constraints on the query string. As outlined in my earlier post Search Web Service, there is support for search operation control parameters (pagination, encoding, etc.), but no inroads are made into the query string itself which is regarded as opaque.
SRU by contrast is an initiative to update Z39.50 for the Web and is firmly focussed on structured queries and responses. Specifically a query can be expressed in the high-level query language CQL which is independent of any underlying implementation. Result records are returned using any declared W3C XML Schema format and are transported within a defined XML wrapper format for SRU. (Note that the SRU 2.0 draft provides support for arbitrary result formats based on media type.)
One can summarize the respective OpenSearch and SRU functionalities as in this table:
| Structure | <th width="33%" align="center">
OpenSearch
</th>
<th width="33%" align="center">
SRU
</th>
|---|
| query | <td align="center">
no
</td>
<td align="center">
yes
</td>
| results | <td align="center">
yes
</td>
<td align="center">
yes
</td>
| control | <td align="center">
yes
</td>
<td align="center">
yes
</td>
| diagnostics | <td align="center">
no
</td>
<td align="center">
yes
</td>
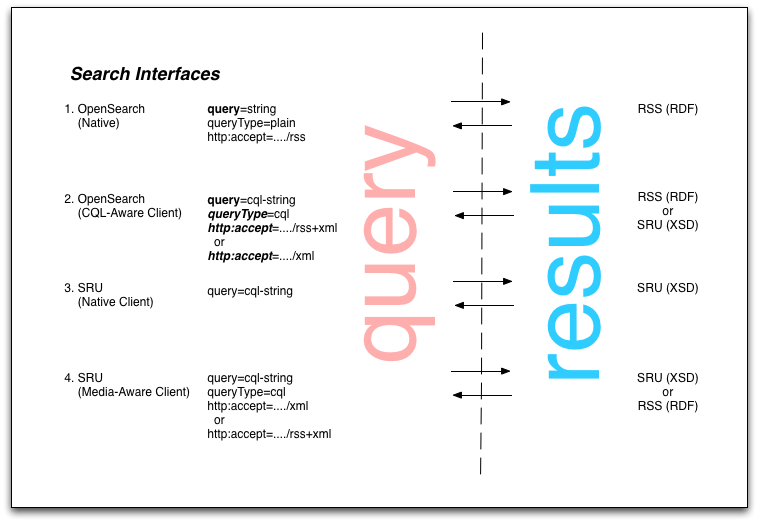
What I wanted to discuss here was the OpenSearch and SRU interfaces to a Search Web Service such as outlined in my previous post. The diagram at top of this post shows query forms for OpenSearch and SRU and associated result types. The Search Web Service is taken to be exposing an SRU interface. It might be simplest to walk through each of the cases.
(Continues below.)
Case 1: OpenSearch (Native Client)
As noted, OpenSearch uses a URL template (declared in an OpenSearch description document) where recognized parameters are mapped to implementation-specific parameters. The bolded parameter “query” in the figure indicates an OpenSearch parameter “searchTerms” which has been mapped to the Search Web Service parameter “query“,
As also noted, SRU 2.0 offers support for alternate result formats (other than SRU XML) by allowing a media type (aka mime type) to be passed in an “http:accept” parameter. There is, however, no OpenSearch parameter corresponding to a format selector, so this must be hard coded directly into the URL template with a value of “application/rss+xml” - the standard media type for an RSS feed which is the common result format for OpenSearch.
(In the diagram I have noted in parentheses that RSS in its RSS 1.0 form is RDF. And that format is a strong candidate for semantic interoperability. An alternate format would be Atom, which could be similarly selected with a value of “application/atom+xml”, but it is difficult to see at this time what advantage Atom confers. It does not conform to the RDF data model but may find better support in code libraries and applications.)
The third parameter shown for Case 1, is “queryType” which is another new SRU 2.0 parameter. I had noted earlier that an OpenSearch query string could be passed directly through to the Search Web Service and its associated CQL parser. It tuns out that this needs to be analyzed further. (And many thanks to Jonathan Rochkind for useful discussions on this.)
I had naively assumed that an OpenSearch query string would either be packed as a CQL string or would be a simple text string which could be interpreted as CQL. The latter interpretation (text string) turns out to be true only for a single bare word or for a quoted string - both of which are recognized CQL query strings (i.e. a single search term which has a default index and relationship to that index). It fails, however, for the more general case of unquoted strings. See table below for these cases.
| Query type | <th width="50%">
Query string
</th>
|---|
| A. bare word | <td align="left">
this
</td>
| B. quoted string | <td align="left">
“this is a query”
</td>
| C. unquoted string | <td align="left">
this is a query
</td>
Case C would fail a CQL parser. So we need to signal to the Search Web Service that this is not a CQL string. And that’s where the “queryType” parameter comes in. If it’s set to “cql” then the query string is to be parsed as CQL, otherwise it must be handled in an alternate fashion. (As of now there is no value set for this parameter that I am aware of so I am using the terms “plain” and “cql” to differentiate.)
How this should be handled by a CQL aware application is not immediately obvious. My first thought was to allow the application to silently quote such a string but that would change the semantics. It would be better to split the string into separate search clauses for each word and to join the search cluases by a default boolean operator, e.g. “AND“, so that case C in the table might be interpreted by the application as:
``[Update - 2009.06.07: As pointed out by Todd Carpenter of NISO (see comments below) the phrase “SRU by contrast is an initiative to update Z39.50 for the Web” is inaccurate. I should have said “By contrast SRU is an initiative recognized by ZING (Z39.50 International Next Generation) to bring Z39.50 functionality into the mainstream Web“.]
[Update - 2009.06.08: Bizarrely I find in mentioning query languages below that I omitted to mention SQL. I don’t know what that means. Probably just that there’s no Web-based API. And that again it’s tied to a particular technology - RDBMS.]
(Click image to enlarge.)
There are two well-known public search APIs for generic Web-based search: OpenSearch and SRU. (Note that the key term here is “generic”, so neither Solr/Lucene nor XQuery really qualify for that slot. Also, I am concentrating here on “classic” query languages rather than on semantic query languages such as SPARQL.)
OpenSearch was created by Amazon’s A9.com and is a cheap and cheerful means to interface to a search service by declaring a template URL and returning a structured XML format. It therefore allows for structured result sets while placing no constraints on the query string. As outlined in my earlier post Search Web Service, there is support for search operation control parameters (pagination, encoding, etc.), but no inroads are made into the query string itself which is regarded as opaque.
SRU by contrast is an initiative to update Z39.50 for the Web and is firmly focussed on structured queries and responses. Specifically a query can be expressed in the high-level query language CQL which is independent of any underlying implementation. Result records are returned using any declared W3C XML Schema format and are transported within a defined XML wrapper format for SRU. (Note that the SRU 2.0 draft provides support for arbitrary result formats based on media type.)
One can summarize the respective OpenSearch and SRU functionalities as in this table:
| Structure | <th width="33%" align="center">
OpenSearch
</th>
<th width="33%" align="center">
SRU
</th>
|---|
| query | <td align="center">
no
</td>
<td align="center">
yes
</td>
| results | <td align="center">
yes
</td>
<td align="center">
yes
</td>
| control | <td align="center">
yes
</td>
<td align="center">
yes
</td>
| diagnostics | <td align="center">
no
</td>
<td align="center">
yes
</td>
What I wanted to discuss here was the OpenSearch and SRU interfaces to a Search Web Service such as outlined in my previous post. The diagram at top of this post shows query forms for OpenSearch and SRU and associated result types. The Search Web Service is taken to be exposing an SRU interface. It might be simplest to walk through each of the cases.
(Continues below.)
Case 1: OpenSearch (Native Client)
As noted, OpenSearch uses a URL template (declared in an OpenSearch description document) where recognized parameters are mapped to implementation-specific parameters. The bolded parameter “query” in the figure indicates an OpenSearch parameter “searchTerms” which has been mapped to the Search Web Service parameter “query“,
As also noted, SRU 2.0 offers support for alternate result formats (other than SRU XML) by allowing a media type (aka mime type) to be passed in an “http:accept” parameter. There is, however, no OpenSearch parameter corresponding to a format selector, so this must be hard coded directly into the URL template with a value of “application/rss+xml” - the standard media type for an RSS feed which is the common result format for OpenSearch.
(In the diagram I have noted in parentheses that RSS in its RSS 1.0 form is RDF. And that format is a strong candidate for semantic interoperability. An alternate format would be Atom, which could be similarly selected with a value of “application/atom+xml”, but it is difficult to see at this time what advantage Atom confers. It does not conform to the RDF data model but may find better support in code libraries and applications.)
The third parameter shown for Case 1, is “queryType” which is another new SRU 2.0 parameter. I had noted earlier that an OpenSearch query string could be passed directly through to the Search Web Service and its associated CQL parser. It tuns out that this needs to be analyzed further. (And many thanks to Jonathan Rochkind for useful discussions on this.)
I had naively assumed that an OpenSearch query string would either be packed as a CQL string or would be a simple text string which could be interpreted as CQL. The latter interpretation (text string) turns out to be true only for a single bare word or for a quoted string - both of which are recognized CQL query strings (i.e. a single search term which has a default index and relationship to that index). It fails, however, for the more general case of unquoted strings. See table below for these cases.
| Query type | <th width="50%">
Query string
</th>
|---|
| A. bare word | <td align="left">
this
</td>
| B. quoted string | <td align="left">
“this is a query”
</td>
| C. unquoted string | <td align="left">
this is a query
</td>
Case C would fail a CQL parser. So we need to signal to the Search Web Service that this is not a CQL string. And that’s where the “queryType” parameter comes in. If it’s set to “cql” then the query string is to be parsed as CQL, otherwise it must be handled in an alternate fashion. (As of now there is no value set for this parameter that I am aware of so I am using the terms “plain” and “cql” to differentiate.)
How this should be handled by a CQL aware application is not immediately obvious. My first thought was to allow the application to silently quote such a string but that would change the semantics. It would be better to split the string into separate search clauses for each word and to join the search cluases by a default boolean operator, e.g. “AND“, so that case C in the table might be interpreted by the application as:
``
Now, of course, we must not expect that a typical OpenSearch implementation would be aware of CQL (or any of the SRU technologies). Instead we can simply indicate in the URL template that the “queryType” is non-CQL, by hard coding “queryType=plain”. The actual URL template which is declared in the OpenSearch description would thus be something like the following (with whitespace added for clarity):
<!-- 1. queryType="plain" -->
<Url type="application/rss+xml"
template="http://www.example/search?
query={searchTerms}
&queryType=plain
&http:accept=application/rss+xml
"
/>
This URL template uses one OpenSearch parameter(“searchTerms”) and that is mapped to the SRU parameter “query”. The SRU 2.0 parameters “queryType” and “http:accept” are wired in. This means that a Search Web Service would be aware of the query, would know that it was not CQL (so might invoke a handler), and would be know that a result set in RSS was required.
Case 2: OpenSearch (CQL-Aware Client)
The above case, works for a general OpenSearch client but now is problematic for a CQL-aware client. With the “queryType” set at “plain” there is no opportunity to indicate that a generic CQL string might be passed instead. We certainly wouldn’t want a non-CQL handler to operate on a valid CQL string. We need to vary the SRU 2.0 parameters and within the scope of OpenSearch this can only be done by recognizing the parameters as OpenSearch extensions. Basically, an extension is nothing more than a separately namespaced element or attribute. Recommendation is that the XML namespace would resolve to a specification document detailing the intention and format of the extension.
The URL template for a CQL-aware OpenSearch description could make use of the “queryType” and “http:accept” parameters as OpenSearch extensions (marked in bold italics in the figure) using a declaration like this:
<!-- 2. queryType="cql" -->
<Url type="application/xml"
xmlns:sru="http://opensearch.example/sru-extension"
template="http://www.example/search?
query={searchTerms}
&queryType={sru:queryType?}
&http:accept={sru:httpAccept?}
"
/>
Note here that both parameters have been specified as being optional. Also the namespace here is pointed at a fictional OpenSearch extension document. (It doesn’t need to point to such a document - could be anything - but it is recommended that there be a specification.)
I’m not aware of any such OpenSearch extension document for SRU currently existing but would be prepared to contribute to drafting such a document. It seems to me that it would be would be very useful for general OpenSearch/SRU compatibility and probably should detail all the SRU 2.0 parameters for “searchRetrieve”. In fact, that document could be the SRU spec itself, once that was established at a fixed URL. (Whether there should be a specific OpenSearch extension document depends on whether it would be useful to provide OpenSearch implementation details.)
Case 3: SRU (Native Client)
This is easy. We’re on home ground now. The query type is by default CQL, and the result format is SRU XML. The only thing that might be specified is “recordSchema” to require a schema for the result records, if there are alternate schemas supported by the Search Web Service. A default for the result records is anyway supplied.
Case 4: SRU (Media-Typed Client)
Again, we’re on familiar ground. For a media-savvy SRU interface we would need to use the SRU 2.0 parameter “http:accept”. This could be used to override the default SRU XML with an alternate format, e.g. RSS.
And that’s about it for this review of aligning the OpenSearch and SRU interfaces. It seems that using URL templates and OpenSearch extensions as indicated should allow for an easy OpenSearch interface onto an SRU-based Search Web Service. At a minimum we just need a permanent URL for the SRU 2.0 spec (when finalized). Alternately a separate OpenSearch extension document could be drafted and registered. That would allow for details specific to OpenSearch to be provided, as well as bringing SRU closer into the OpenSearch realm. And such a document could be created now and updated with the URL for the SRU 2.0 spec as it progresses from draft to final.



