13 minute read.A summary of our Annual Meeting
The Crossref2024 annual meeting gathered our community for a packed agenda of updates, demos, and lively discussions on advancing our shared goals. The day was filled with insights and energy, from practical demos of Crossref’s latest API features to community reflections on the Research Nexus initiative and the Board elections.

Our Board elections are always the focal point of the Annual Meeting. We want to start reflecting on the day by congratulating our newly elected board members: Katharina Rieck from Austrian Science Fund (FWF), Lisa Schiff from California Digital Library, Aaron Wood from American Psychological Association, and Amanda Ward from Taylor and Francis, who will officially join (and re-join) in January 2025. Their diverse expertise and perspectives will undoubtedly bring fresh insights to Crossref’s ongoing mission.
The meeting started with a recap of our mission and priorities. Ed Pentz reiterated the Research Nexus vision of increasing transparency of the connections that make up the scholarly record and underpin the research ecosystem.
Crossref is dedicated to openness, community ownership, and a stable, accessible infrastructure that researchers, publishers, funders, and institutions can rely on for the long term. This is demonstrated by Crossref’s commitment to the the Principles of Open Scholarly Infrastructure (POSI), which constitute commitments to building a resilient and transparent infrastructure for research—sustainability, community governance, and openness. Ed emphasized how Crossref is aligning with these principles and collaborates with other adopters to reflect and continuously align these with the needs of the scholarly community, with a public consultation on proposed revisions to POSI forthcoming next year.
Ginny Hendricks highlighted key membership and metadata trends. She noted that as of 2024, half of Crossref members are based in Asia. This year, as always in recent years, we saw many new organisations from Indonesia, Turkey, India, and Brazil join us. Removing those fast-growing countries for the chart’s clarity, we can see that some of the next most active countries are Pakistan, Mexico, Spain, Bangladesh, and Ecuador, among others.
There are now ~163 million open metadata records with Crossref DOIs, and Ginny pointed out increases in the registration of preprints, peer-review reports, and grants. In terms of metadata elements, it’s good to see that more publishers recognize the importance of including abstracts and ROR IDs in their metadata records. Also, in line with the community’s concerns about integrity, our members have been enriching their records with direct assertions of retractions.
Then, Ginny went on to report on the progress towards our strategic goals:
- Contribute to an environment where the community identifies and co-creates solutions for broad benefit
- A sustainable source of complete, open, and global scholarly metadata and relationships
- Manage Crossref openly and sustainably, modernizing and making transparent all operations so that we are accountable to the communities that govern us.
- Foster a strong team because reliable infrastructure needs committed people who contribute to and realize the vision and thrive in doing it.
Demos
Lena Stoll and Patrick Vale’s session gave members a practical preview of our latest tools.
Patrick started by reflecting on the challenge of making our identifiers useful for people using screen readers (and other assistive technologies). He thanked all who responded to our past consultation on the topic and presented the Crossref DOI Accessibility Enhancer – the browser plug-in initially available for Firefox (and soon also for Chrome). He shared the Gitlab repo for anyone interested in trying it and invited feedback as we’re hoping to iterate on this.
Patrick then went on to talk about our openness to community contributions to Crossref tools, with an example of the recent contribution from CWTS Leiden to our Participation Reports. Thanks to their work, our members can now see the proportion of works they’ve registered that include affiliation information and ROR IDs, alongside the previously available key metadata such as references, abstracts, ORCID iDs, funding information, or Crossmark.
Finally, Lena demonstrated the latest extension of our record management tool that’s just been made available to make manual registration of metadata records for journal articles easier. The new form is flexible and driven by our metadata schema. Importantly for our members, it simplifies the workflow with input validations and automated ISSN matching, and it enables members to register author affiliations with an integrated ROR look-up. We hope this will support our smaller members, who are relying on our helper tools to register their content.
Throughout the session, members were encouraged to use these tools and explore new resources available through Crossref. We believe that by taking advantage of these resources, you can enhance your research and publishing experience, and contribute to the growth and development of the scholarly community.
The discussion about open scholarly infrastructure
The panel on open scholarly infrastructure brought together experts with a wide range of experience in the field. Moderated by Lucy Ofiesh, Crossref’s Chief Operating Officer, the discussion featured six invited speakers who shared their insights on the opportunities and challenges facing the scholarly ecosystem: Ed Pentz, Crossref; Sarah Lippincott, Dryad; Amélie Church, Sorbonne University; Joanna Ball, DOAJ; Ann Li, Airiti; and Richard Bruce Lamptey, Kwame Nkrumah University of Science and Technology.
The panel talked about what openness in scholarly infrastructure means, why it’s important, its sustainability, and how to tackle challenges and gaps across the ecosystem. They highlighted frameworks like the Principles of Open Scholarly Infrastructure (POSI), the Barcelona Declaration, and the FOREST Framework as key tools for guiding work on governance, sustainability, and equity. The discussion highlighted the need for more collaboration, inclusivity, and practical ways to ensure open infrastructure remains sustainable in the long run.
They also stressed how openness supports research integrity. How transparent systems allow researchers to question methods, verify findings, and preserve data. Amelie Church expanded on this point, underscoring the important role of open infrastructure in addressing challenges to integrity. She explained that such transparency enables the scholarly community to scrutinize research processes, ensuring the quality of outputs and their impact on society. Without openness, researchers face barriers to maintaining trust in their work, making open infrastructure necessary for research integrity and public confidence in science.
“By focusing on accessibility, transparency, and community engagement, open infrastructure can reshape academic and research ecosystems in transformative ways.” ~Richard Bruce Lamptey
Regarding sustainability, Sarah Lippincott stressed the importance of aligning funding models with community needs while addressing governance challenges. She pointed out that while initial funding can launch infrastructure, long-term sustainability requires consistent community investment and robust governance frameworks. This balance, she explained, is essential to ensure equity and transparency.
Collaboration was another important topic. Joanna Ball and Sarah Lippincott shared examples of how pooling expertise and resources—such as in the global support for ROR—can strengthen systems and make them more sustainable. These initiatives show the power of collective efforts in addressing technical and resource barriers. However, inclusivity remains an ongoing challenge.
The panel discussed the ways in which language barriers, resource limitations, and reliance on proprietary systems continue to exclude researchers from underrepresented regions. Ann Li highlighted how addressing these disparities is critical to ensuring the global accessibility of open infrastructure. By fostering inclusive practices, the scholarly community can mitigate biases and build tools that reflect a broader range of research contributions.
”My hope is that open infrastructure can have the resources that it needs to thrive, not just merely survive, and also that open infrastructure communities and organisations look to the value of frameworks that we’ve talked about today to help align themselves and improve their policies and practices, because there’s always room for growth, even in the best, most well-intentioned communities.” ~Sarah Lippincott, Dryad
The panel wrapped up the discussion by expressing optimism for the future of open scholarly infrastructure and emphasized the importance of continued investment, collaboration across organisations, and transparency in operations. The discussion reinforced the idea that open infrastructure provides a strong foundation for research that is equitable, sustainable, and accessible to all.
We enjoyed talks from our community about increasing their participation in the Research Nexus by adopting, using and enhancing metadata in different ways. Robbykha Rosalien hosted talks from the EuropePMC, Dutch Research Council, eLife, and CSIRO featured in Session I, and Amanda French hosted CLOCKSS, Sciety, and Redalyc in Session II.
Michael Parkin talked about preprints in Europe PMC. Europe PMC is a database for life science literature and a platform for content-based innovation. They started indexing preprints via Crossref REST API in 2018. Michael presented their work on discoverability of preprints in their database, including reflections on early challenges, as well as the latest efforts in surfacing available community reviews.
Hans de Jonge talked about the Dutch Research Council’s (NWO) dedication to open science, with policies ensuring that publications and data funded by NWO are openly available. They embrace open science principles for their own metadata and is a signatory of the Barcelona Declaration on Open Research Information. Hans focused on NWO’s recent introduction of Grant IDs through Crossref’s Grant Linking System (GLS). He shared their approach, the motivations behind introducing Grant IDs, and some challenges they faced.
Frederick Atherden explained how eLife, a nonprofit led by scientists, use Crossref’s Grant Linking System to include grant DOIs in their publication metadata. It allows authors to add grant DOIs during submission, and they developed a tool to match grant numbers with DOIs during the proofing process to improve accuracy. Their goal is to follow best practices for metadata, making content easier to find and link to.
Brietta Pike covered how CSIRO is working to improve metadata quality for its journals, making research more discoverable and trustworthy. CSIRO faced challenges like inconsistent XML tagging, outdated systems, and data loss. To address these, they formed a project team, created a clear XML stylesheet, and updated their workflows. Recent progress includes better funding data, clearer license information, and more complete affiliation tagging. These efforts aim to support a more transparent and accessible research environment.
Alicia Wise of CLOCKSS talked about recent collaborations seeking to safeguard our cultural and scholarly heritage over the long term. CLOCKSS, a community-run archive, is dedicated to preserving scholarly content to remain accessible and unchanged for future generations. True preservation requires securely storing content in trusted archives that are actively maintained. A group of librarians and publishers developed a guide to help publishers preserve content, they also established an archival standard for EPUB formats to ensure ebooks can be stored effectively, and launched a pilot project to track preserved books, helping libraries and scholars identify safely stored titles.
Mark Williams from Sciety talked about how Sciety uses Crossref metadata to create detailed preprint histories. By partnering with organisations and communities worldwide, Sciety platform gathers public reviews, highlights, and recommendations on preprinted research, helping researchers evaluate the quality and relevance of new studies. Through linking related preprints and journal articles, Sciety builds a connected view of each research work. Although challenges like inconsistent terminology and identifier gaps persist, these efforts enhance the visibility and credibility of preprints.
Arianna Becerril-García of AmeliCA/Redalyc shared insights on diamond open-access journals in Latin America. Redalyc is an open-access infrastructure that supports journals by providing free services like visibility and production tools. Redalyc has a role in sustaining Latin America’s unique approach to open-access publishing, where most journals are backed by academic institutions and public funds, allowing free access for both readers and authors. Arianna stressed the need to treat these journals as digital public goods and urged the communities they serve to help ensure their long-term sustainability. Despite limited resources and global under-recognition, these journals serve an international research audience, including authors from Europe, Africa, and Asia. Redalyc and other open infrastructures play a key role by offering tools that reduce production co-sts and improve discoverability, all without financial barriers. Noted was how this approach aligns with UNESCO’s open science framework, which promotes inclusivity and addresses long-standing inequalities in scholarly publishing.
Afternoon of more resources and updates from Crossref
After a mid-day break (in Europe), Luis Montilla kicked off the second session with a practical tutorial of Crossref’s REST API. Following his last year’s intro to the Crossref API, this time he offered a step-by-step guide to help attendees maximize the API’s capabilities for metadata retrieval with advice on:
- Managing large data requests with pagination and iterations
- Incorporating safety mechanisms - to avoid hitting rate limits, Luis recommended adding pauses between requests and sharing example scripts to streamline this.
For those interested in learning more, look at the new Crossref API Learning Hub— a new resource offering guides, scripts, and training materials to simplify complex queries. Please share questions about things you’re not sure about in our community forum, to help guide development of future demos.
Patricia Feeney followed with updates on metadata schema changes. She introduced our recent shift to integrate the Funder Registry with ROR, which allows members to use a single identifier system, simplifying data management by reducing redundancy. Patricia explained that, for now, the current identifiers remain valid, so members won’t need to make immediate changes. She also outlined planned support for version metadata, typed citations, and future plans to expand support for contributor role vocabularies, and invited community participation in a planned multilingual metadata working group.
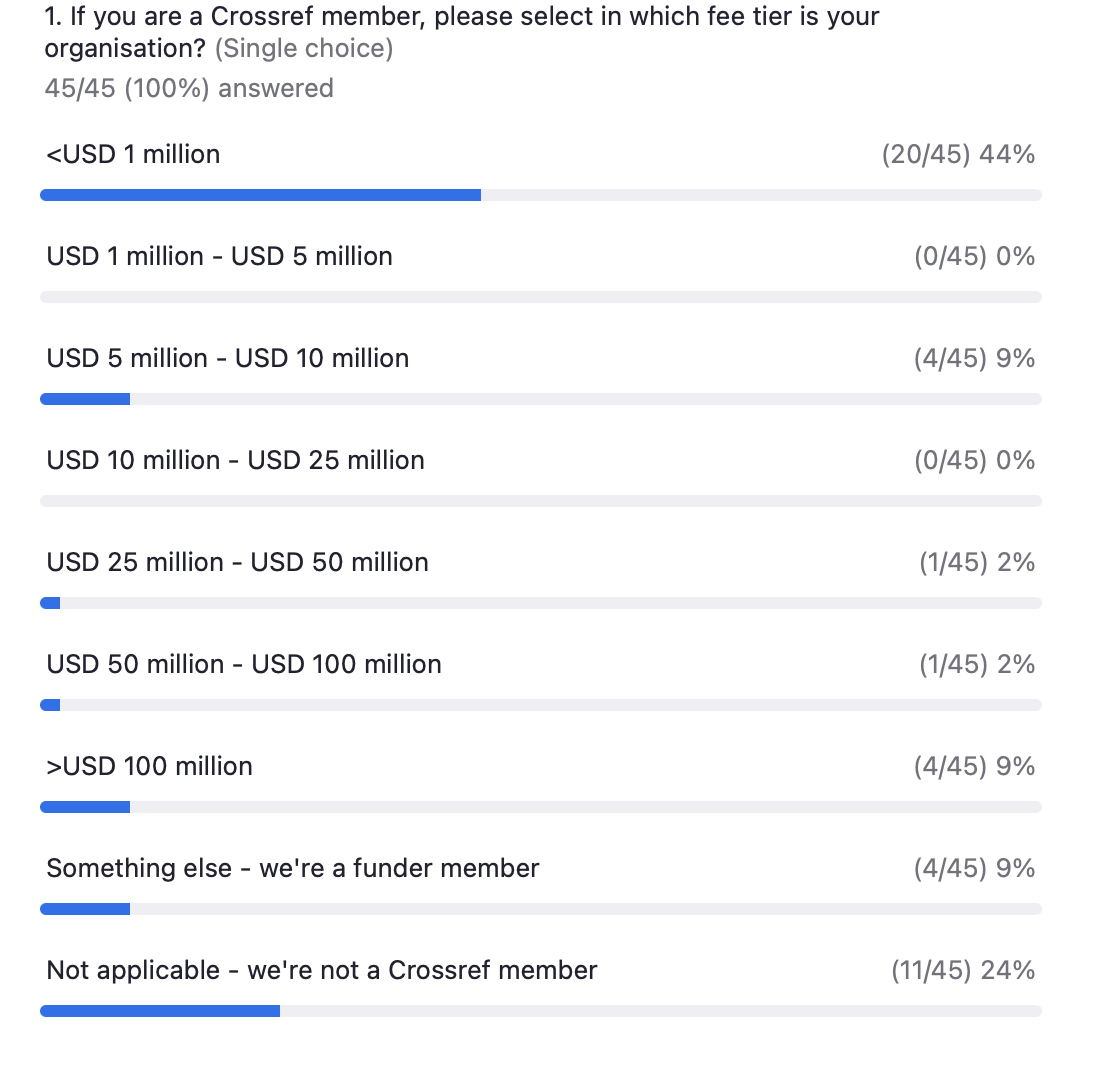
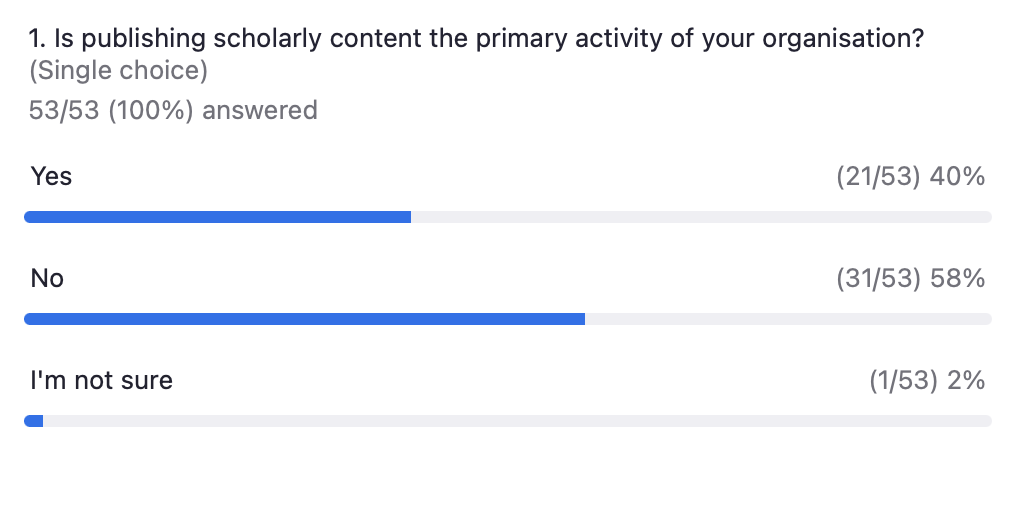
Next, Kora Korzec offered an update on the progress in our research on Resourcing Crossref for Future Sustainability and opened up a discussion about the best ways of assessing our members’ size and ability to pay. In light of our ambition to streamline discounts, we also invited suggestions for discounts to support accessibility and fuller participation in the Research Nexus.
As part of the discussion, we’ve learned who was in attendance during the session:
We’ve heard a lot of support for our current GEM program. While it was clear from our poll that publishing revenue is not the most relevant measure of size or capacity for all those present – establishing a good alternative proved challenging. The idea of considering the size of the organisation as its largest entity has been discussed, and important points were raised about budgets in different types of distributed organisations (e.g., on the position of libraries within large universities).
The official Annual Meeting part commenced after the discussion, with a report on the State of Crossref from Lucy Ofiesh, and commenced with our Board election. Lucy highlighted some of the key accomplishments of the year so far, including:
- Research for Resourcing Crossref for Future Sustainability (RCFS)
- Integrity of the Scholarly Record (ISR)
- Grant Linking System (GLS) reached 5 years
- Automated some very manual membership processes
- Released new form for journal article record registration
- Upgraded Participation Reports to include Affiliations and ROR IDs
- Launched a new API Learning Hub
- Paused further development of a Relationships API
- Migrated to a new open-source database
- Schema development - ROR as Funder identifiers
- REST API bug fixes and metadata consistency fixes.
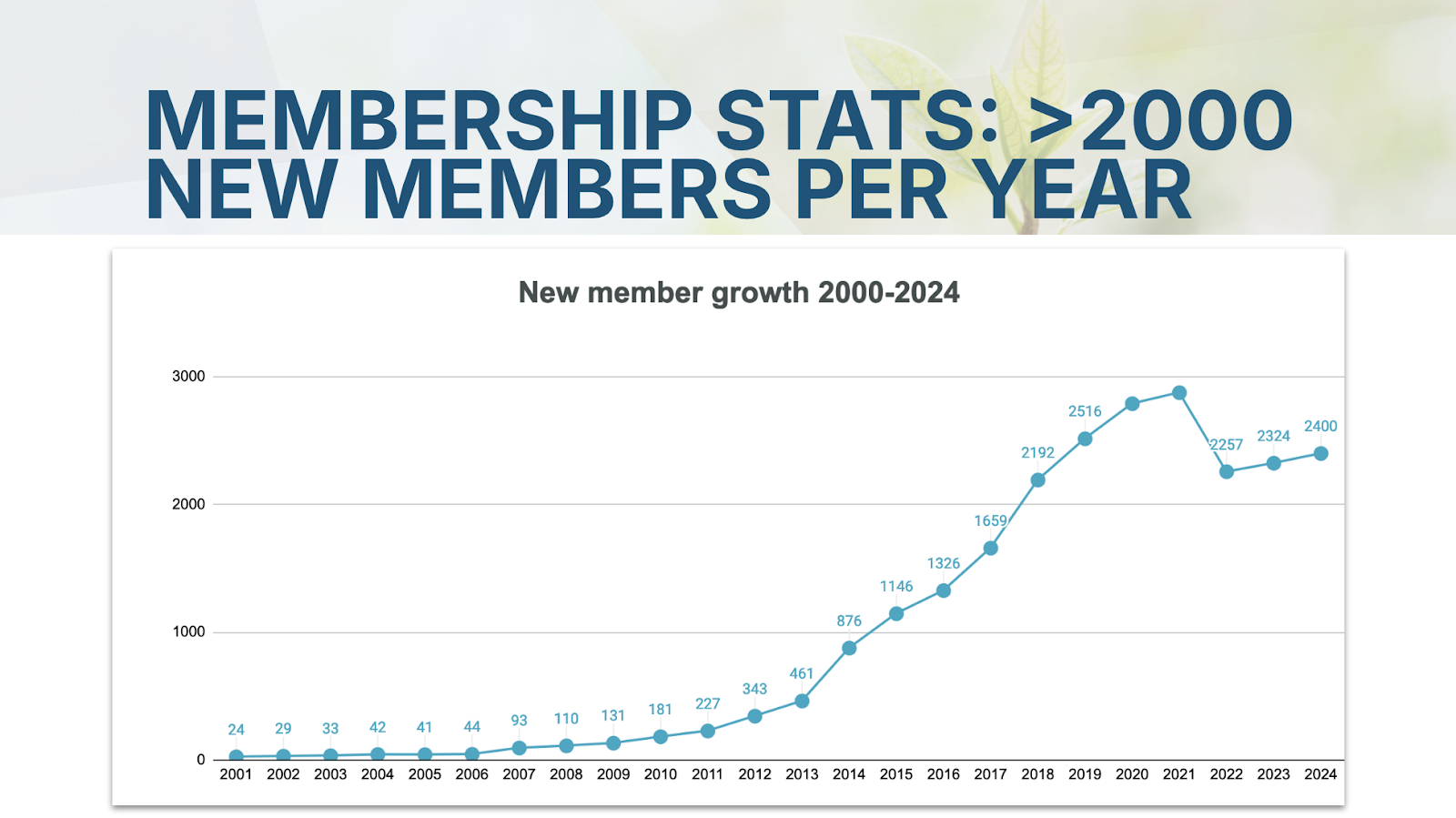
Then she reflected on the membership growth––Crossref is now made up of 21,000 organisations from 160 countries. We reviewed our 2024 year-end financial forecast. As we’re bouncing back from COVID-19, our travel expenses have grown this year, and so have the fees for cloud services hosting. These are all as planned and happen in the context of healthy growth, including that from adoption and increased usage of paid services. We’re in a healthy financial position as membership revenue and usage fees, like content registration and Similarity Check document checking fees, continue to grow from the previous year.
Thank you to everyone who joined us for Crossref2024. This year’s meeting showcased our collective dedication to advancing open, accessible research infrastructure and underscored the power of collaboration in building a stronger scholarly community. As we reflect on the rich discussions and insights shared during the event, it’s clear our community is committed to advancing open and sustainable scholarly infrastructure.
Looking ahead, we’ll continue collaborating with members and partners to tackle challenges, expand accessibility, and foster collaboration. A key focus will be enhancing tools and metadata standards to serve the community better. Through innovative solutions and strategic initiatives like the Research Nexus, our collective efforts will make research more connected and accessible for all.
For anyone who couldn’t attend live, recordings are now available on our website. We’re excited to see how the ideas exchanged during this meeting spark progress across the scholarly ecosystem in the coming months.