3 minute read.100,000,000 records - thank you!
100,000,000. Yes, it’s a really big number—and you helped make it happen. We’d like to say thank you to all our members, without your commitment and contribution we would not be celebrating this significant milestone. It really is no small feat.
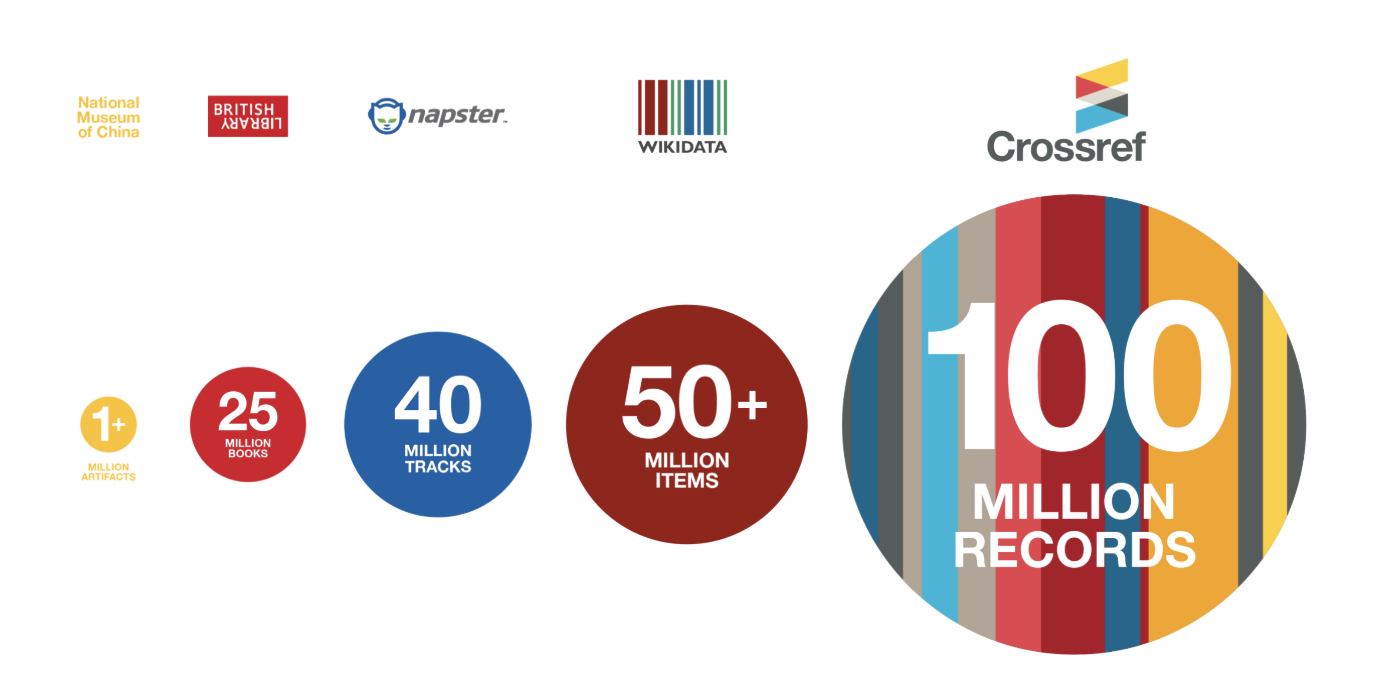
To help put this number into context; the National Museum of China has just over 1 million artifacts, the British Library has around 25 million books, Napster has 40 million tracks, and Wikidata currently contains 50 million+ items.
Digging into the 100 Million
Within these 100 Million registered content records there are many different record types.
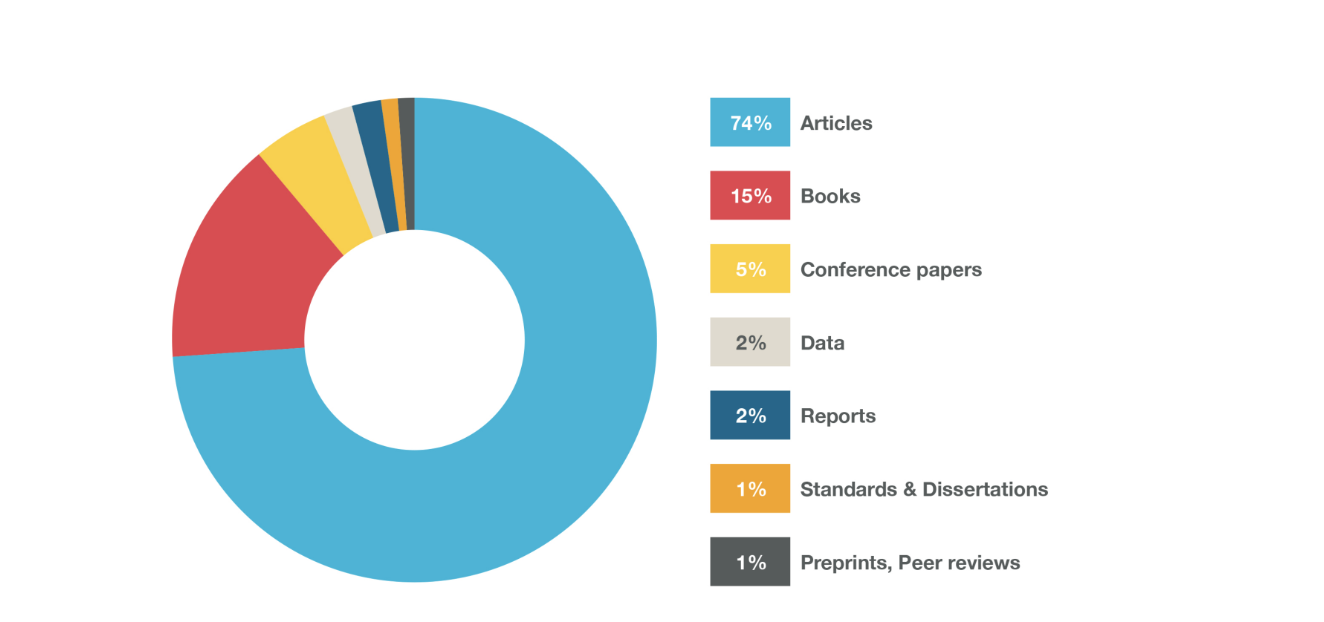
And within these record types, more than 69 million records have full-text links, 31 million+ have license information and 3 million+ contain some kind of funding information. An overview of these and other Crossref vital statistics is available on our dashboard.
100 Million—what does your contribution look like?
Our recently-launched participation reports allow anyone to see the metadata Crossref has. It’s a valuable education tool for publishers, institutions and other service providers looking to understand the availability of the metadata they have registered with us.
Through an itemized dashboard Participation Reports allows you to monitor the metadata you are registering, even if this work is done by a third party or another department. You can see for yourself where your gaps are, and what you could improve upon. Next to each metadata element, there’s a short definition, letting you know more about it, and—crucially—what practical steps you can take to improve the score.
The dashboard provides the percentage counts across ten key metadata elements: References, ORCID iDs, Funder Registry IDs, Funding award numbers, Crossmark metadata, License URLs, Text-mining links, Similarity Check URLs, and Abstracts.
And not only can you see your own metadata—the dashboard enables you to view the registered metadata of all our 11,076 members.
How are these 100 Million content records being used?
Every service we provide is based on our metadata, and our APIs expose all of that metadata. Over the past year or so we have been collecting use cases from members that actively utilize the Metadata APIs and have turned these into a Metadata APIs blog series so that we can share these stories of how our metadata is used with the wider community.
A big number. Even bigger ambitions.
Gaps or errors in metadata are passed on to thousands of other services, which causes problems downstream and means we all suffer. So it makes sense for the metadata you deposit to be as accurate and complete as possible. The more elements there are to the metadata, the higher the chance of others finding and using the content. We aim to continually find effective ways to communicate this wider story around the importance of open infrastructure and metadata.
Over the years we’ve made great progress in connecting information about researchers, their affiliations, grants, and research outputs. Imagine how much more powerful this information would be if supplemented by more comprehensive, accurate, and up-to-date metadata.
Sources - all data as of Sept 26, 2018
National Museum of China has 1,050,000 artifacts
The British Library has around 25 million books, more than any other library
Wikidata currently contains 50,290,632 items
NAPSTER currently has 40 million tracks (Napster is known as Rhapsody in the US)



